高速化のために
目次
高速化の工夫
仮に、命令を読み込んで、データをリレー記憶から2つ読み込んで、乗算を行い、リレー記憶に書き戻しを行ったとしましょう。
この時間を素直に足し合わせてみます。
1) 紙テープ装置からの命令読み込みに 16ms
2) リレー記憶からのデータ読み込みを2つで 40ms
3) 乗算に 16ms
4) リレー記憶への書き込みで 20ms
1命令に 92ms 、実際にはもっと細かな遅延もあるでしょうし、100ms 程度と言っていいでしょう。
1秒に 10命令しか実行できません。
「素直に」足し合わせたから遅く見えるのです。
SSEC では、同時に出来ることは同時にやってしまうように、いろいろな工夫がありました。
VLIW
現代の CPU では、Itanium とか、少し前なら Crusoe コアや i860 とか…
いずれにしても一般にはなじみのない CPU で使われている技術ですが、VLIW と呼ばれるものがあります。
Very Long Instruction Word 。非常に長い命令語、という意味です。
普通は、一つの「命令語」には、一つの指示しか含まれません。
しかし、VLIW では、一つの「命令語」に複数の指示が含まれます。
なんのことはない、2つとか4つとかの命令をまとめて読み込むだけなんですけどね。
現代的には、それらの命令は「同時に実行できることを保証されている」ことになっています。
CPU の回路を削減できるメリットがあるのですが…まぁ、詳細はWikipediaでも読んでください。
さて、SSEC の命令も VLIW になっています。
命令を読み込む際は、2命令を同時に読み込みます。
命令詳細は次回やりますが、1命令は10進数で20桁。
これは、紙テープの1行に相当しますから、「同時に」2命令を読み込むのには、2本の紙テープを利用します。
読み込んだ内容は、リレーで構成された「命令記憶装置」に保持してから解釈します。
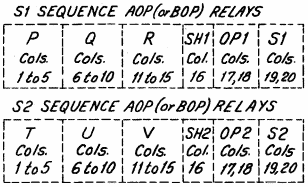
RELAYS となっているので、この「記憶回路」がリレーだったことがわかる。
S1 と S2 の2命令を同時に読み込む。
その命令の内容は混乱を避けるため別の名前が与えられているが、基本的に同じものとわかる。
AOP (or BOP)となっているのは、この「記憶回路」が A/B の2組あるため。
2命令を同時に読み込むのは、紙テープが物理動作を伴い遅いことをカバーするためです。
2本の紙テープを同時に読み込めば、読み込み速度は2倍になりますから。
VLIW と言っても、演算回路は1つしかないため、2命令が同時に実行できるわけではありません。
パイプライン
パイプラインは、現代の多くの CPU で使用される技術です。
CPU が命令を実行する際には、命令を読み込み、必要なデータを準備し、演算を行い、結果をメモリに保存し…と、細かな動作を繰り返します。
1つの動作を行っている際は、使われない回路は休んでいます。
これは無駄なので、ある命令が演算をしているときに、次の命令のためのデータを準備し、さらに次の命令を読み込む…というような仕組みがあります。
この方式を、パイプラインと呼びます。
![]() SSECの「命令記憶装置」は、当然2命令を同時に読み込めるようになっています。
SSECの「命令記憶装置」は、当然2命令を同時に読み込めるようになっています。
それだけでなく、「A面」と「B面」の2つの記憶装置があり、命令の解釈中に次の命令を読み込めるようになっています。
回路の意味を理解する必要はない。
「OPERATIONAL SIGN」(命令)に関するもので、上に「A side」、下に「B side」と書いてある。
命令を実行中に次の命令を読み込めるように、同等の回路が A/B 2組作られていた。
命令の実行が終わると、A面とB面を「切り替え」ます。
切り替えは 1ms 以下の時間で完了します。
これにより、紙テープ装置の「遅さ」はほとんど隠されてしまい、次々命令を実行できることになります。
演算装置は、IBM 603 に相当する部分で、1つしかありませんでした。
そのため、演算は順次行われます。VLIW ですが、同時実行はできないのです。
しかし、演算実行中に、次に実行する命令に必要な「データ」へのアクセスが行われていました。
また、演算実行後は、データがメモリに書き込まれるのを待たず、次の命令の実行に入りました。(詳細後述)
命令読み込み、データの準備、演算、結果の保存が分離され、同時に行われているのです。
これは、パイプラインに他なりませんでした。
装置の読み込み同時アクセス
周辺機器にアクセスするためのバスは8本あり、同時使用可能でした。
命令実行時には2つのデータを読み込む必要があります。
そして、命令は2つ同時に取り込まれます。実行は順次ですが、データの準備などは取り込まれた時点で開始されます。
合計で、4本のデータを同時に取得に行きます。
バスとレジスタはセットになっています。
周辺機器アクセスの際には必ずバスを指定する必要があり、それは同時にレジスタへのアクセスを意味しました。
2つの命令それぞれで3つ、合計6つの「データ」を必要とするのに対し、レジスタは8本ですから厳しい制約です。
レジスタが元々「遅いバスのキャッシュ」として作られていることを考えれば当然なのですが。
バス(レジスタ)のみを指定し、周辺機器を指定しないこともできます。
この場合は、レジスタ自体を装置として使用することになり、1ms 以下でアクセスが完了しました。
1つ目の命令で出力としてレジスタを指定し、続く命令で入力としてそのレジスタを使う、というような例は数多く見られます。
このような使い方の場合、レジスタの破壊は無いため、2命令で同じレジスタを使っても問題ありません。